
강
[Algorithm] Scala 를 이용하여 PageRank 알고리즘 배워보기 본문
PageRank 알고리즘은 구글이 웹 페이지를 추천해 줄 때 적용한 대표적인 알고리즘으로 유명 합니다.
간단히 설명드리자면, 각 페이지들이 링크로 관계가 형성되어 있을 때 중요한 페이지 일수록 링크를 많이 받는 것을 가정하고 점수를 매기는 알고리즘 입니다.
예를 들어 제가 어떤 페이지를 참고하여 그 페이지를 참고 링크로 포스팅에 올려두었다면 제 페이지와 링크를 건 페이지간의 관계가 형성 되어 내부적으로 점수를 매길 것 입니다. 만약 제 페이지의 점수가 기존에 굉장히 높았다면 제가 링크를 건 페이지의 점수도 따라서 점수가 높아질 것 입니다.
이런식으로 페이지들 관계에 따라서 점수가 달라지며 높은 점수를 보유한 페이지가 검색에서 상단에 나타나게 될 것 입니다.
이번 포스팅에서는 이러한 PageRank를 Scala로 직접 구현해보고 결과값을 살펴볼 것 입니다.
https://databricks.com/ 에서 코드를 실행했습니다.
실험 데이터셋 세팅
import org.apache.spark.HashPartitioner
val links = sc.parallelize(List(("MapR",List("Baidu","Blogger")),("Baidu", List("MapR")),("Blogger",List("Google","Baidu")),("Google", List("MapR")))).partitionBy(new HashPartitioner(4)).persist()
var ranks = links.mapValues(v => 1.0)예제 실험 데이터셋은 총 4개의 node(페이지)의 관계들을 가지고 진행합니다.
MapR, Baidu, Blogger, Google 각 node들 관계를 생성해 줍니다.
PageRank 알고리즘을 실행시키기 전 모든 node의 rank값을 1로 초기화 합니다.
val contributions = links.join(ranks).flatMap { case (url, (links, rank)) => links.map(dest => (dest, rank / links.size)) }contributions.collect생성한 관계에 대한 데이터셋과 rank값을 join하여 최종 실험 데이터셋을 만듭니다.
1번 실행
val ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85*v)ranks.collectPageRank 알고리즘을 전체 데이터셋에 대해서 1번 실행시켜 보았습니다. PageRank에서는 임의로 아무런 관계가 없는 페이지로 방문을 시키는 random suffer의 비율을 정해야 하는데 이번 테스트에서는 0.15(15%)로 설정해 주었습니다.
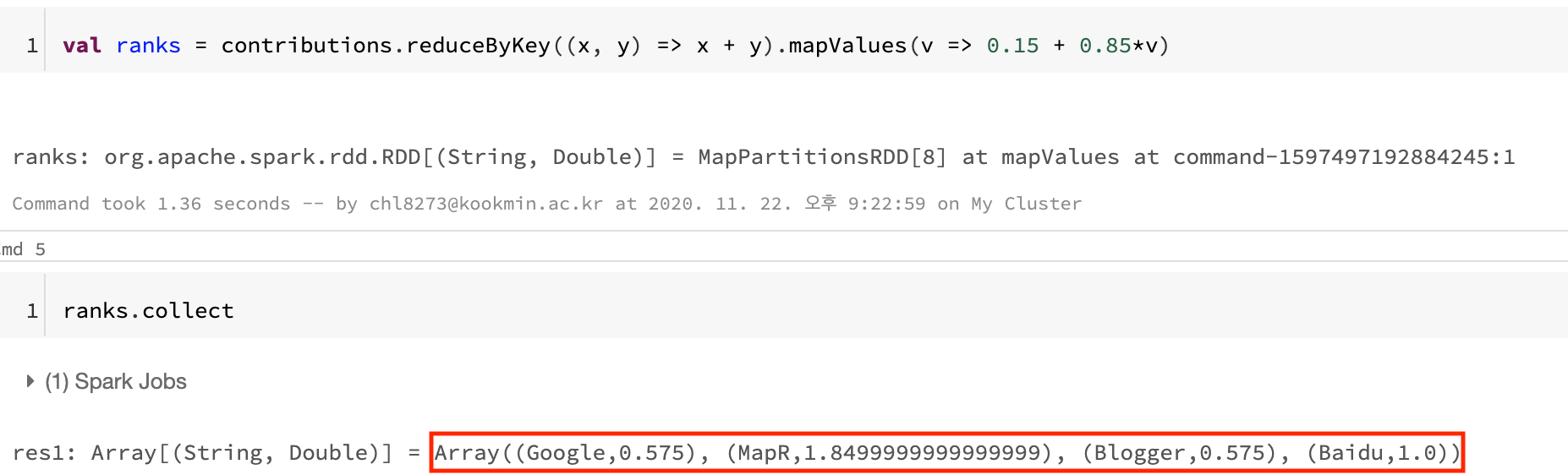
위와 같이 현재 node들이 각각 특정 rank값을 가지고 있음을 확인할 수 있습니다.
이러한 같은 과정을 반복하면, 각 페이지들이 점점 특정값에 수렴하는 결과를 보이게 됩니다. 그 수렴한 결과값이 해당 페이지의 rank값이 됩니다.
계속 더 반복시켜 보겠습니다.
5번 반복
var ranks = links.mapValues(v => 1.0)
for (i <- 1 to 5) {
val contributions = links.join(ranks).flatMap { case (url, (links, rank)) => links.map(dest => (dest, rank / links.size)) }
ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85*v)
}
ranks.collect기존 값에 대해서 rank를 다시 초기화 해준 후 for문을 이용하여 반복횟수를 설정합니다.

1번 실행 결과와는 값이 조금 달라진 것을 확인할 수 있습니다. 반복 횟수를 늘려 더 실험해 보겠습니다.
10번 반복

20번 반복

반복이 증가함에 따라서 각 node들의 rank값들이 특정값에 수렴하는 결과를 보입니다. MapR의 경우가 rank값이 가장 높게 나온 것을 볼 수 있습니다. 실험 데이터셋에서 페이지 간의 관계를 달리 해준다면 결과값도 달라질 것 입니다.