
강
[DL] 딥러닝 추론이란? 본문
딥러닝은 크게 두가지 단계로 나눌 수 있다. 한가지는 대다수의 사람들이 알고 있는 학습(Training) 이다.
학습과정의 특징은 축적된 많은 데이터를 바탕으로 각 신경망들의 Weight를 업데이트 해가며 딥러닝 모델을 만들어 가는 과정이다. 반면 추론(Inference)은 학습을 통해 만들어진 모델을 실제로 새로운 입력 데이터에 적용하여 결과를 내놓는 단계이다.
학습과 추론 비교
학습과 추론의 차이점을 조금 더 살펴보겠다.

그림에서 보면 알 수 있듯, 학습을 위해서는 많은 데이터가 필요하다. 그리고 그 데이터 들은 우선 순방향 전파를 통해 각 신경망을 거쳐가고 Loss function을 통해 에러율이 얼마나 되는지 판단하고, 그 에러율을 줄이기 위해 역방향 전파로 다시 신경망을 반대로 지나가면서 각 신경망의 Weight들을 바꾸는 것이다.
하지만 모델을 만들어 가기 위한 학습과는 달리 추론의 목적은 현재 데이터에 대해서 해당 모델이 원하는 작업을 수행해 주는 것이다. 이미지 분류 모델의 예를 들면, 사람과 고양이를 분류하는 학습된 모델이 있다고 했을 때 단순히 내가 고양이 사진을 인풋 데이터로 넣으면 고양이라고 분류 해주면 되는 것이다. 따라서 추론 과정에서는 순방향 전파만이 일어난다. 또한 학습 과정에서는 모델이 데이터를 넣을 때 마다 Weight가 업데이트 되며 조금 씩 바뀌어 간다면 추론 과정에서는 인풋 데이터를 어느 정도 넣는 지 상관 없이 모델의 Weight는 고정적이다. 한마디로 해당 모델이 고양이 분류를 5%의 오차율로 수행했다면 같은 데이터에 대해서 다음번에도 5%의 오차율로 수행할 것이라는 것이다.
그렇다면 실제 학습과 추론 작업을 수행할 때 어떤 차이점이 있을까?
학습은 추론에 비해 많은 데이터를 바탕으로 훨씬 긴 시간에 걸쳐 진행되며 여유로운 데드라인을 가지고 진행될 것이다. 반면 추론작업은 실제로 사용자가 해당 모델에 원하는 사항을 요구하고 그것을 실시간으로 수행하는 서비스에 활용된다. 따라서 사용자에 훨씬 직면에 있는 작업이며 작업이 실시간으로 대응 되어야 하고 사용자가 원하는 시간과 요청 개수에 맞추어 대응해야 한다. 실시간으로 대응해야 한다는 것은 요청이 어떤 경우에는 적게 들어오고 어떤 경우에는 폭발적으로 늘어날 수 있다는 것을 의미한다.
내가 좋아하는 NBA 농구 선수인 스테판 커리를 예로 들며 학습과 추론 비교를 마무리 하겠다.

스테판 커리는 3점슛을 잘쏘는 선수로 유명하다. 그는 농구 시합이 없을 때에도 수만번의 3점슛을 다양한 각도, 위치(많은 데이터셋)에서 던질 것이다(순방향 전파). 그리고 던질 때마다 들어가는 슛과 들어가지 않는 슛이 있을 것이고 들어가지 않는 슛을 보완하기 위해 슛 쏘는 자세를 교정하며(역방향 전파) 열심히 슛을 더 쏠 것이다.
그렇게 연습을 한 스테판 커리는 팀의 승리를 책임지기 위해 다소 위험한 상황에 놓였다. 팀이 101: 103 2점차로 지고 있는 상황에 경기 시간은 4초 밖에 남지 않은 것이다. 그 상황에서 타임 아웃을 부른 감독은 스테판 커리에게 이렇게 얘기한다 "4초 안에 3점슛을 넣어줘". 감독의 주문(사용자의 요구 사항)을 들은 스테판 커리는 어느 위치, 각도에서건 감독의 요구에 맞추기 위해 그동안 연습해온 슛을 바탕으로 3점슛을 시도하고 성공하거나 실패할 것이다(추론 결과). 이것이 딥러닝의 추론 과정이라고 볼 수 있다. 사용자의 요구에 맞추어 원하는 작업을 수행하는 것, 그것이 딥러닝의 추론 작업의 특징이다.
사용자의 요구사항 : SLO
앞선 내용에서 언급했듯 추론에서는 사용자의 요구 사항을 충족하는 것이 중요하다. 딥러닝 추론에 관련된 여러 논문들을 읽어보면 SLO 혹은 SLA라는 단어를 많이 사용하는 것을 볼 수 있다. SLO란 Service Level Objectives를 줄인말이며 말 그대로 서비스 단에서 충족해야할 목적이라고 해석하면 된다. 참고로 SLA는 Servcie Level Agreement로 비슷한 뜻을 가진다. 보통 SLO를 주로 쓰는 듯 하다.
SLO에 대한 예시를 하나 들어보겠다.
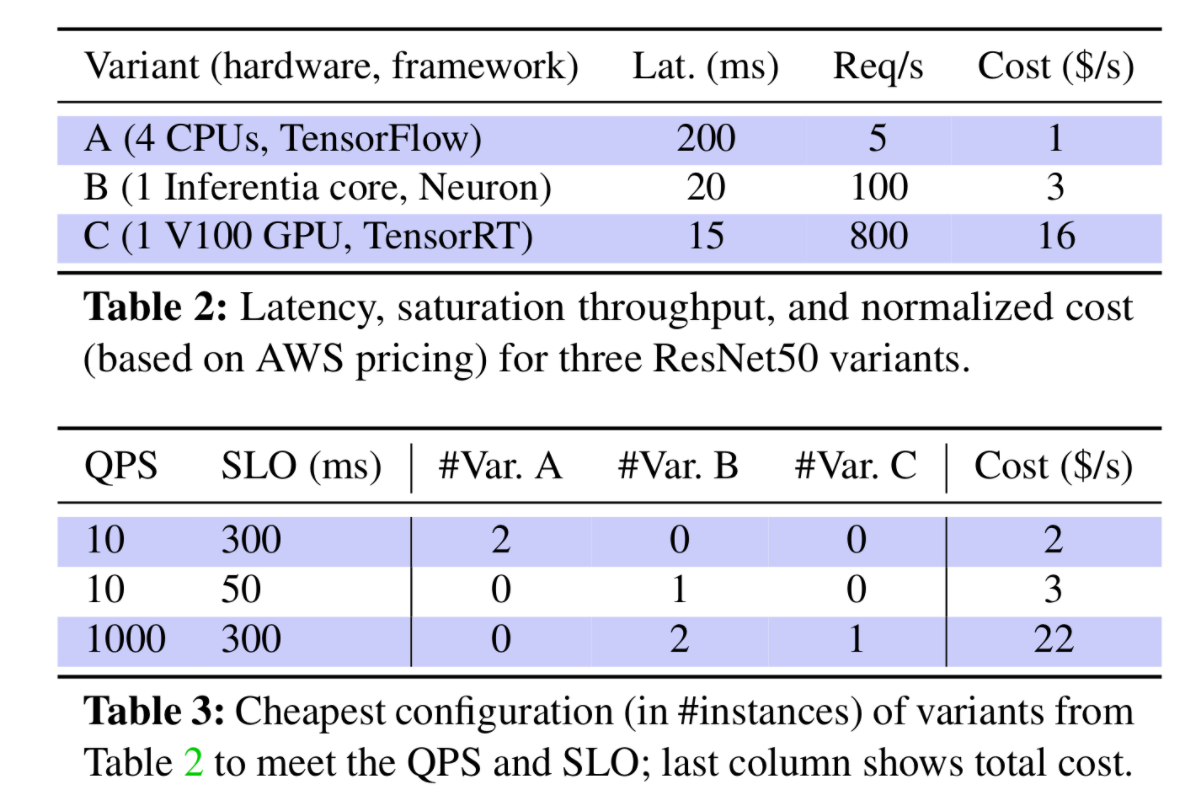
위 그림에서 Table2는 3종류의 추론 작업을 돌릴 수 있는 Varient 즉, 선택할 수 있는 가짓수를 나타낸다. Variant A, B, C는 각각 서로 다른 하드웨어,프레임워크로 구성되어 있으며 각 Variant별로 처리하는 대에 걸리는 Latency와 Request수, 드는 비용인 Cost가 명시되어 있다. 예를 들어 Variant A는 5개의 요청을 200ms에 1달러를 소모하며 수행하는 것이다.
Table3은 서로 다른 사용자의 요구사항에 맞는 적절한 추론 옵션을 선택하는 시나리오를 보인다. QPS는 처리해야할 쿼리의 수를 의미하고 SLO는 제한 시간을 의미한다. 이 논문에서는 SLO를 처리 시간으로 설정해두었지만 정확도 또한 SLO에 속할 수 있다는 것을 기억해두자. 따라서 첫번 째 경우인 QPS 10, SLO 300ms의 경우 Variant A를 2개 사용하여 처리하는 것이 가장 효율적임을 알 수 있다. 왜냐하면 Variant B나 C를 사용하면 더 빨리 처리할 수 있었겠지만, 그에 따라서 Cost가 증가했을 것이고 SLO가 300ms로 다소 넉넉했기 때문이다.
그러면 같은 QPS양에서 SLO가 50ms로 제한된 경우를 살펴 보자. 이 경우 Variant A를 사용할 수는 없을 것이다. 왜냐하면 SLO 요구 조건을 충족할 수 없기 때문이다. 따라서 Variant B 1개로 해당 요구를 수행하는 것이 가장 효율적이다. Variant C를 사용했다면 Cost가 16으로 훨씬 비싸게 수행하는 것이기 때문이다.
이번엔 마지막으로 QPS가 1000으로 많아진 상황을 살펴보자. 이 경우에는 Variant B 2개, Variant C 1개를 사용하여 수행하는 것이 가장 효율적이라고 명시되어 있다. 이 경우 QPS가 높기 때문에 Variant A를 선택하는 것은 비효율적일 것이고 Cost가 비싸지만 처리 가능한 Request수가 많은 Variant C를 1개, 남은 QPS를 Variant B로 처리하는 경우가 가장 효율적이다.
이처럼 사용자의 요구사항에 따라서 가지고 있는 하드웨어, 프레임워크, 딥러닝 모델 등의 옵션이 달라짐을 알 수 있고 요구사항에 맞게 효율적인 옵션을 선택하는 것이 중요하다. 위의 경우에서 정확도 등의 요구 사항이 더 추가된다면 조금 더 선택하기에 복잡해질 것이다. 따라서 현재 딥러닝 추론 분야는 미리 선택될 수 있는 Varient들을 정리해두고 이를 시스템적으로 최적화하여 SLO에 알맞은 Variant를 자동적으로 선택할 수 있도록 시도하는 연구가 활발히 진행되고 있다.
하드웨어 가속기
앞서 추론을 수행하는 데에 다양한 Varient 중 하드웨어가 관여하는 것을 보았다. 실제로 딥러닝 추론 분야에서는 프레임워크, 데이터의 사이즈, 모델의 종류 등 다양한 요소가 성능에 관여하지만 대표적으로 하드웨어를 선택하는 것이 가장 우선으로 꼽힌다.
CPU와 GPU 그리고 TPU

CPU와 GPU는 대표적인 추론 하드웨어로 사용된다. 추론에서의 CPU는 상대적으로 값싼 비용에 범용적으로 모델들을 문제 없이 처리할 수 있다는 장점이 있다. 밑에서 다룰 다른 하드웨어 가속기의 경우 지원하지 않는 모델들이 있는 경우도 있기 때문에 범용성 또한 장점으로 잡을 수 있다. 하지만 값이 싼 만큼 처리량이 다소 떨어지며 이는 인풋 데이터의 배치 사이즈가 커질 수록 단점이 두드러진다. GPU의 경우 CPU보다 비싸지만 높은 처리량을 가지고 이는 특히 인풋 데이터의 배치 사이즈가 커질 수록 장점으로 작용한다. 따라서 SLO 중 처리 시간이 엄격한 경우 CPU보다 사용하기에 적합하다.
아래 그림은 딥러닝 추론에서 유명한 MArK 논문(https://www.usenix.org/conference/atc19/presentation/zhang-chengliang)에서 가져왔다. 딥러닝 추론 실시간 서비스를 시스템적으로 구축해놓은 논문이니 참고해보아도 좋을 듯 하다.

MArK에서는 CPU, GPU, TPU에서 배치 사이즈를 증가해보며 추론 작업을 해본 결과를 그래프로 나타낸 것이다. TPU는 Google에서 지원하는 하드웨어 가속기이다.
실험 결과를 살펴보면 배치 사이즈가 낮을 때에는 비슷한 처리 시간을 가지는 반면 비용은 CPU가 가장 저렴하여 효율적임을 보인다. 하지만 배치 사이즈가 증가 할수록 GPU가 처리시간이 앞서고 처리 시간이 빠른 만큼 하드웨어가 쓰이는 시간이 적기 때문에 비용면에서도 효율적임이 두드러 진다. TPU의 경우 GPU보다 처리 시간이 비슷하거나 더 느린 반면 비싼 비용이 드는 것으로 보아 가장 비효율적인 하드웨어 가속기로 논문에서는 보였다. 논문에서는 아직까지 Google TPU는 추론보다는 학습에 적합한 하드웨어라고 설명을 하고 있으나 추후 발전될 여지가 보인다.
AWS EIA, AWS Inferentia
클라우드 서비스로 유명한 AWS에서도 딥러닝 추론을 위한 하드웨어 가속기 서비스를 제공한다.
EIA는 Elastic Inference Accelerator의 줄임말로 평소 CPU기반으로 컴퓨팅 작업이 이루어 지다가 추론 작업을 대상으로만 네트워크 통신을 통해 GPU기반의 EIA가 추론 작업을 하고 결과 데이터를 CPU에 전달한다. EIA별로 medium, large, xlarge로 type이 정해져 있고 다수의 EIA 하드웨어를 한번의 추론 작업 시나리오에 사용할 수 있어 다양하게 추론 작업에 사용할 수 있다. 추론 작업에 EIA를 이용하도록 하기 위해 EIA 전용 SDK를 AWS에서 제공하고 있으며 EIA를 호출하는 SDK의 함수를 통해 쉽게 추론 작업을 수행할 수 있다.

AWS Inferentia는 Neuron Chip이라고 하는 GPU기반 하드웨어를 AWS 전용 인스턴스에서 제공한다. Neuron Chip으로 추론 작업을 수행하기 위해서는 EIA와 마찬가지로 AWS에서 제공하는 SDK를 활용해야 한다. EIA와 다른 점은 EIA는 단순히 기존 CPU에서 수행하던 모델로 함수한 호출하면 되지만, Inferentia의 경우 Neuron Chip으로 추론할 수 있도록 모델을 컴파일 해야한다. 따라서 CPU에서 수행하던 모델을 컴파일 하는 과정에서 Neuron Chip이 지원하지 않는 Layer가 포함되어 있을 경우 사용에 제약을 받을 수 있다. 이러한 제약에도 Inferentia가 가치 있는 이유는 CPU보다는 처리량이 빠르고 GPU보다는 가격적으로 저렴한 중간 위치에 있기 때문이다.
AWS EIA, AWS Inferentia 모두 비교적 최근에 발표된 하드웨어로 연구를 해볼 가치가 있는 하드웨어이고 연구 결과에 따라서 추론 시스템에 도입해볼 여지가 있다. 앞으로가 기대되는 하드웨어들이다.
이외에도 Nvidia에서 다양한 하드웨어를 제공해 주고 있으며 하드웨어 말고도 프레임워크(Tensorflow, Pytorch, TensorRT, MxNet 등)와 딥러닝 모델 종류 등 고려해볼 다양한 선택 요소들이 존재한다.
마무리
딥러닝 추론 분야는 학습 분야에 비해 비교적 적은 연구가 이루어 졌고 최근 딥러닝을 실시간으로 서비스화 하면서 필요성이 많아진 분야이다.

AWS에서는 딥러닝 학습단계에 비해 추론단계에서 전체 비용의 90%가 든다고 하고 다른 회사에서도 점점 딥러닝 추론 분야에 대한 중요성을 인식하는 중이다. 딥러닝 추론의 실시간 서비스에서 가변적인 요청량들을 어떻게 효율적으로 처리할 것인지에 대해 지금도 여러 연구가 진행되고 있다. 사용자와 밀접한 위치에서 만족도 높은 서비스를 제공하기 위해 발전시키는 것이 정말 매력적인 분야이다.
참조
- https://lifeisenjoyable.tistory.com/7
- https://arxiv.org/abs/1905.13348?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+arxiv%2FQSXk+%28ExcitingAds%21+cs+updates+on+arXiv.org%29
- https://overface.tistory.com/542#
- https://www.usenix.org/conference/atc19/presentation/zhang-chengliang
- https://towardsdatascience.com/a-complete-guide-to-ai-accelerators-for-deep-learning-inference-gpus-aws-inferentia-and-amazon-7a5d6804ef1c
- https://www.intel.co.kr/content/www/kr/ko/artificial-intelligence/posts/deep-learning-training-and-inference.html
- https://developer.nvidia.com/blog/inference-next-step-gpu-accelerated-deep-learning/
- https://www.hellot.net/news/article.html?no=52620
'AI > Deep Learning' 카테고리의 다른 글
| Tensorflow MLFlow 사용해보기 (0) | 2023.06.26 |
|---|---|
| [DL] Keras로 imagenet 모델 save(저장), load(불러오기) (0) | 2021.10.01 |

