
강
Tensorflow MLFlow 사용해보기 본문
본 포스팅은 “MLFlow를 활용한 MLOps” 책을 통해 학습하고 추가적으로 공부하여 정리한 글입니다.
실습 코드 전체 버전과 Tensorflow 의외에 다른 프레임워크를 다룬 코드는 깃허브에 정리되어 있습니다.
머신러닝 파이프라인 자동화
머신러닝과 딥러닝 모델의 수요는 ChatGPT의 등장과 함께 더더욱 늘어나고 있고 앞으로도 늘어날 것 이다.
회사 입장에서 AI 모델을 사용하기 위해 일반적으로 아래의 과정을 따른다.
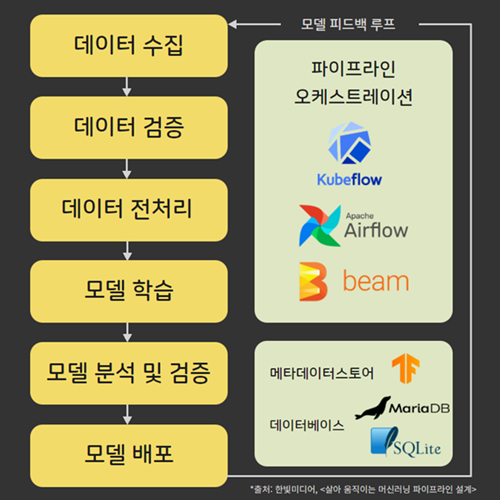
이러한 배포 구조를 ML 파이프라인이라고 부르며 모든 과정은 한번만 수행되는 것이 아닌 파이프라인 배포 상황에 따라서 유동적으로 조정될 여지가 있어 반복적인 성향을 띈다.
따라서 Frontend, Backend, Data Engineer 등의 반복되는 업무를 자동화 해주고 인프라를 구성해주는 DevOps 처럼, 반복되는 ML 파이프라인 과정을 자동화하고 인프라를 구성하는 직무로 MLOps라는 것이 생겨나기도 했다.
ML 파이프라인 자동화 수요 또한 높아짐에 따라서 개발자 입장에서 사용가능한 여러 소프트웨어와 툴들도 생겨나는 추세이다.
대표적으로 MLFlow, Kubeflow, Airflow 등등 파이프라인 인프라 구성을 위한 툴들과 Tensorflow Serving, BentoML 등 모델 배포/서빙을 위한 서비스 등등 사용할 모델과 추구하는 인프라 방향에 따라서 여러 장단점을 가진 서비스들이 존재한다.
오늘은 그중 MLFlow를 Tensorflow를 통해 실습해보는 과정을 다룰 것이다.
MLFlow
MLFlow는 앞서 언급한 ML 파이프라인 구성을 위한 API를 제공해주는 오픈 소스이다. MLFlow는 이미 존재하는 프로젝트에 쉽게 도입이 가능하다는 장점이 있다.
기존 코드를 최소로 변경해 MLFlow API를 추가하면 프로젝트의 모델 및 다양한 지표들을 추적할 수 있으며 개별 모델 간의 모든 지표를 비교해 최적의 모델을 선택할 수 있다.
실제로 실습 코드를 통해 기존의 Tensorflow(Keras) API와 거의 동일하게 코드 사용이 가능함을 볼 수 있다.
Tensorflow와 MLFlow 사용 실습
본 포스팅에서는 실습 구성과 핵심 코드 설명 위주로 진행하여 직접 실습 진행을 위해 아래 깃허브 링크를 참조해주세요.
0. 실습 환경 구성
실습 환경은 다음과 같다
- Google Colab
- python Jupyter 코드를 실행시키기 위해 사용
- Databricks
- Colab에서 실행한 코드를 MLFlow UI로 확인하기 위해 해당 서비스를 사용한다
(계정이 없다면 회원가입이 필요하며, 본 포스팅에서는 Community 회원으로 14일 무료 계정을 통해 진행했습니다.) - https://community.cloud.databricks.com/
- Colab에서 실행한 코드를 MLFlow UI로 확인하기 위해 해당 서비스를 사용한다
1. 필수 라이브러리 설치 및 Import
!pip install mlflow==1.10.0
#scikit-learn 1.2 버전 아래에서 진행해야 원활히 진행 가능
!pip install scikit-learn==1.1.0import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import sklearn
from sklearn.metrics import roc_auc_score # 해당 API가 1.2버전 아래에서만 지원
import mlflow
import mlflow.tensorflow
print("Tensorflow: {}".format(tf.__version__))
print("scikit-learn: {}".format(sklearn.__version__))
print("Numpy: {}".format(np.__version__))
print("MLFlow: {}".format(mlflow.__version__))
print("Matplotlib: {}".format(matplotlib.__version__))실습을 위해 mlflow 및 scikit-learn를 설치한다
(책에서 사용하는 scikit-learn의 “roc_auc_score” api가 1.2버전을 넘어가서부턴 다르게 바뀌어 본 포스팅에서는 다운그레이드 하여 진행했다)
2. Colab과 Databricks 연동
MLFlow UI를 사용하기 위해 Colab에서 Databricks를 연동하고 인증 작업을 진행한다.
#databricks cli를 통해 Colab과 Databricks 연동
!databricks configure --host https://community.cloud.databricks.com/
#mlflow가 databricks를 트래킹하도록 설정
mlflow.set_tracking_uri("databricks")
databricks_email = "<본인의 Databricks 계정 이름>"
# MLFlow에 기록할 실험 이름 (자유롭게 변경 가능)
mlflow_experiment = "TF_Keras_MNIST"
# Databricks에 로그인, mlflow 실험 생성, experiment가 없을 경우 새로 생성 후 연결
mlflow.set_experiment(f"/Users/{databricks_email}/{mlflow_experiment}")
3. 데이터셋 로드, Tensorflow 모델 구성
제공된 코드에서 “데이터 처리”, “Tensorflow 모델 구성” 코드를 통해 진행한다.
해당 코드를 통해 아래의 과정들이 진행된다.
- MNIST 데이터셋 로드 및 전처리
- 간단한 TF 모델 Layer 구성 및 컴파일 작업
4. MLFlow를 사용해 모델 학습 및 추론 지표 로깅
# databricks와 연동 (앞서 이미 진행했다면 생략 가능)
databricks_email = "<본인의 Databricks 계정 이름>"
mlflow_experiment = "TF_Keras_MNIST"
mlflow.set_experiment(f"/Users/{databricks_email}/{mlflow_experiment}")
# MLFlow가 로깅을 시작하도록 지시하는 코드
with mlflow.start_run():
# MLFlow에 Tensorflow/Keras 모델과 관련된 파라미터, 지표 기록
mlflow.tensorflow.autolog()
model.fit(x=x_train, y=y_train, batch_size=256, epochs=10)
preds = model.predict(x_test)
preds = np.round(preds)
eval_acc = model.evaluate(x_test, y_test)[1]
auc_score = roc_auc_score(y_test, preds)
print("eval_acc: ", eval_acc)
print("auc_score: ", auc_score)
# MLFlow에 추가적인 메트릭 기록
mlflow.tensorflow.mlflow.log_metric("eval_acc", eval_acc)
mlflow.tensorflow.mlflow.log_metric("auc_score", auc_score)
# MlFlow 로깅 작업 종료
mlflow.end_run()
코드를 보면 알 수 있듯이, mlflow 관련 코드를 제외하고는 일반적인 Tensorflow의 모델 학습 코드로 구성되어 있다.
- model.fit()을 통해 train 데이터로 배치 사이즈와 Epoch수를 정해 학습
- model.predict()를 통해 학습된 모델을 를 통해 테스트 데이터셋으로 추론
- model.evaluate()를 통해 추론한 데이터를 바탕으로 모델을 평가
이렇게 기존 Tensorflow 코드 구조를 해치지 않고 간단한 with 절과 로깅을 위한 코드만 추가하여 모델 지표 로깅 및 모니터링이 가능하다.
- autolog()를 통해 tensorflow에서 제공하는 기본적인 모델 파라미터와 지표 기록 가능
- log_metric()을 통해 Tensorflow API로 모델을 평가한 메트릭에 대해서 추가적인 기록 가능
5. MLFlow UI 확인 (Databricks)
4번 과정까지 진행했다면, 이제 Databricks 사이트에 접속해 로그인을 진행한다.
로그인 후 Workspace - Users - [계정 이름] 의 순서로 클릭한다.
클릭 하면 앞서 코드를 통해 생성한 Experiment인 “TF_Keras_MNIST”가 생성되었을 것이다. 클릭한다.
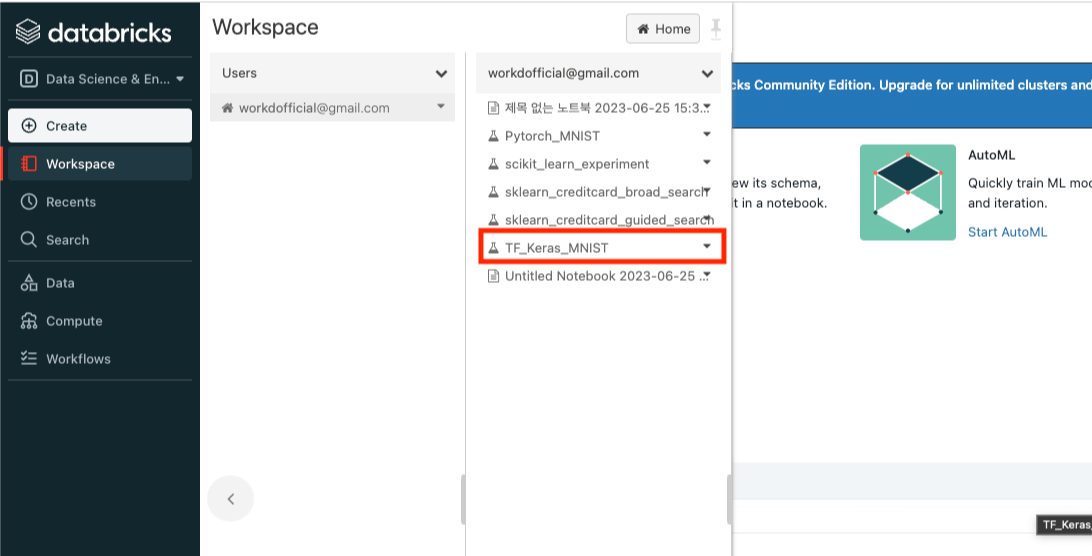
여러번 실행했다면, 여러개의 실행 로그가 남겨져있을 것이다. 가장 최근에 생성된 실행 로그를 클릭한다.
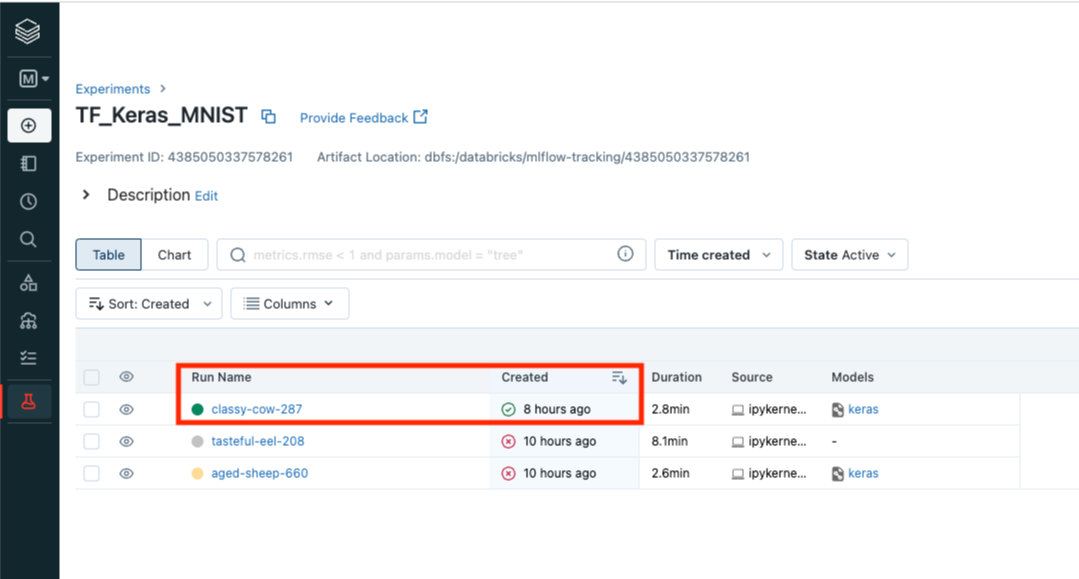
그렇다면 Tensorflow를 통해 실행한 모델 정보를 MLFlow UI에서 살펴볼 수 있다.

크게 3가지 정도를 위 UI에서 파악 가능하다.
- Run ID : 실행된 모델에 대한 ID이다. MLFlow API와 ID를 통해서 모델을 다시 실행해보거나 메트릭을 파악할 수 있다
- Metrics : 모델에 대한 메트릭 정보를 볼 수 있다. 기본적인 모델 정확도와 Loss 정보를 확인할 수 있으며 추가로 MLFlow API로 기록한 acc_score, eval_acc 값또한 나타내어져 있다
- Model 정보: Databricks 저장소 자원을 통해 실행한 모델이 저장되어 있음을 알 수 있으며 모델에 대한 정보 및 tensorboard log가 기록되어 있음을 알 수 있다

추가적으로 모델 Parameters 정보도 UI에서 파악 가능하다. 모델을 훈련할 때 사용했던 배치 사이즈 수, Epoch수 등이 기록되어 있으며 그밖의 모델에 관여할 수 있는 여러 파라미터 값들이 저장되어 있고 쉽게 확인 가능함을 알 수 있다.
MLFlow에 적재된 모델 로드 및 실행
앞서 MLFlow UI를 통해 복사한 Run ID를 코드에 넣어준다.
# MLFlow UI에서 생성된 실행 ID 확인 후 기입
RUN_ID = "<Your RUN ID>"
# 실행 ID를 통해 실행된 모델을 불러올 수 있다
loaded_model = mlflow.keras.load_model(f"runs:/{RUN_ID}/model")
eval_loss, eval_acc = loaded_model.evaluate(x_test, y_test)
preds = loaded_model.predict(x_test)
preds = np.round(preds)
eval_auc = roc_auc_score(y_test, preds)
print("Eval Loss:", eval_loss)
print("Eval Acc:", eval_acc)
print("Eval AUC:", eval_auc)
해당 코드를 통해 MLFLow는 Run ID로 모델 실행에 대해 관리한다는 것을 알 수 있다. 실행 결과를 살펴보면 앞서 실행한 모델 결과와 정확히 일치할 것 이다.
RUN ID를 통해 ML 파이프라인 개발자는 언제든 모델을 다시 실행해 보거나 해당 모델의 파라미터, 메트릭을 파악할 수 있으며 모델을 조정해가며 발전시켜 나갈 수 있다.
MLFlow에서 사용한 load_model() 함수를 보면 알 수 있듯이 기존 tensorflow, keras에서 사용하는 load_model API와 동일함을 알 수 있다. 또한 로드된 모델의 추론 방식 또한 크게 다르지 않아 개발자 입장에서 적은 러닝커브로 쉽게 MLFlow를 도입할 수 있게 된다.
정리
Tensorflow와 MLFlow를 사용해 모델 파라미터와 메트릭을 쉽게 로깅할 수 있었다. MLFlow UI를 통해 시각적으로 표현하는 서비스를 Databricks와 함께 사용하여 확인했었으며 이러한 서비스들은 ML Engineer가 모델을 조정하고 튜닝하는데에 큰 도움을 줄 수 있다.
MLFlow는 Tensorflow와 더불어 Pytorch, Scikit-Learn 등등 기존 여러 머신러닝, 딥러닝 프레임워크에 대한 API를 지원하며 큰 코드 수정없이 도입 가능한 점 또한 보았다.
본 포스팅에 참고한 “MLFlow를 활용한 MLOps”에서는 추가적으로 클라우드 환경에서 MLFlow를 통해 모델을 배포하는 내용도 있어 크게 참고할 만 한 것으로 보인다. 추후 가능하다면 이 부분도 포스팅해보면 좋을 것 같다고 생각이 든다.
출처
- “MLFlow를 활용한 MLOps” 책
- https://m.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS8716308407
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Keras로 imagenet 모델 save(저장), load(불러오기) (0) | 2021.10.01 |
|---|---|
| [DL] 딥러닝 추론이란? (4) | 2021.09.20 |

