
목록전체 글 (41)
강
해야하는 이유 github에 push를 할때 username, password를 묻는데 계정을 등록하면 더이상 입력할 필요 없다. 계정 등록이 되어 있지 않은 상태에서 push를 하면 github에 잔디가 생성되지 않는다. 사용자, 이메일, 패스워드 등록 ** 8월 부터 github에서 패스워드가 아닌 인증 토큰을 발급하여 인증하도록 하므로 password 자리에 인증토큰을 등록줍니다 ** git config --global user.name "github 닉네임" git config --global user.email "github 이메일" git config --global user.password "github 인증토큰" 인증 토큰 발급 방법은 아래 링크를 참조하시면 좋아요 https://manch..
 [Github] 토큰 생성과 로그인 방법
[Github] 토큰 생성과 로그인 방법
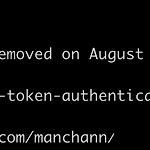
평상시와 같이 repository에 commit을 push하기 위해 비밀번호를 입력했으나 다음과 같은 메세지를 확인했습니다. 알고보니 2021년 8월 13일 부터 Github에서 인증할 때 계정암호의 방식을 허용하지 않게 되었다고 합니다. remote: Support for password authentication was removed on August 13, 2021. Please use a personal access token instead. remote: Please see https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/for more infomations. 따라서 저와 같이 암호를 사용하여 ..
 [AWS EC2] AWS EC2에서 Jupyter Notebook 환경 구축
[AWS EC2] AWS EC2에서 Jupyter Notebook 환경 구축
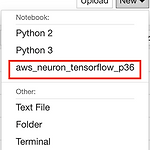
python과 관련된 코드로 과제를 하거나 연구를 할 때에 Jupyter Notebook을 많이 활용합니다. 보통 local 환경에서는 (자기 노트북, 데스크탑 등) 많이들 손쉽게 Jupyter Notebook을 실행하여 진행하지만 클라우드 환경인 AWS EC2와 같은 환경에서는 활용하지 못하는 경향이 있는 듯 합니다. 그래서 이번 포스팅에서는 AWS EC2환경에서 어떻게 Jupyter Notebook을 실행하여 사용할 수 있을 지 안내합니다. AWS EC2 ubuntu 18 환경을 기준으로 작성하였습니다. Jupyter Notebook 실행 환경 구성 1. jupyter notebook을 설치 sudo apt-get update sudo apt-get install python3-pip sudo pip..
 [Algorithm] Scala 를 이용하여 PageRank 알고리즘 배워보기
[Algorithm] Scala 를 이용하여 PageRank 알고리즘 배워보기
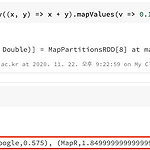
PageRank 알고리즘은 구글이 웹 페이지를 추천해 줄 때 적용한 대표적인 알고리즘으로 유명 합니다. 간단히 설명드리자면, 각 페이지들이 링크로 관계가 형성되어 있을 때 중요한 페이지 일수록 링크를 많이 받는 것을 가정하고 점수를 매기는 알고리즘 입니다. 예를 들어 제가 어떤 페이지를 참고하여 그 페이지를 참고 링크로 포스팅에 올려두었다면 제 페이지와 링크를 건 페이지간의 관계가 형성 되어 내부적으로 점수를 매길 것 입니다. 만약 제 페이지의 점수가 기존에 굉장히 높았다면 제가 링크를 건 페이지의 점수도 따라서 점수가 높아질 것 입니다. 이런식으로 페이지들 관계에 따라서 점수가 달라지며 높은 점수를 보유한 페이지가 검색에서 상단에 나타나게 될 것 입니다. 이번 포스팅에서는 이러한 PageRank를 Sc..
 [AWS S3] AWS S3에 버킷들이 쌓여있을 때 정리하는 프로그램
[AWS S3] AWS S3에 버킷들이 쌓여있을 때 정리하는 프로그램
이번 포스트에서는 AWS S3에 버킷들이 많이 쌓여있을 때 필요한 버킷인지 아닌지 버킷안에 오브젝트를 보며 정리해 나갈 수 있는 프로그램을 소개합니다. shell script 기반으로 제작 되었습니다. 다음의 깃헙에 소스파일이 공유되어 있습니다. https://github.com/manchann/KMU-s3-delete 환경 세팅 AWS CLI를 사용하기 위해 다음과 같는 명령어를 사용하여 계정 로그인을 합니다. asw configure 실행 파일의 권한을 변경합니다. sudo chmod +x task.sh 작업을 시작하기 위해 명령어를 입력합니다. source task.sh local 폴더에 s3_bucket_list.txt라는 파일이 생길 것입니다. s3 버킷 이름에 대한 리스트가 저장되어 있고 ta..
 [Azure Function] Microsoft Azure의 Function Log 확인하기
[Azure Function] Microsoft Azure의 Function Log 확인하기
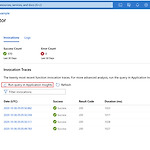
서버리스에 대해 여러 연구가 진행되고 있는 만큼 Microsoft의 FaaS 모델인 Function또한 관심이 높아 지고 있습니다. 이번 포스트 에서는 Function의 log를 어떻게 확인할 수 있는지 알아 보겠습니다. Azure 포털에서 Function 탭들 중 Monitor를 클릭합니다. 그 후 Run query in Application Insights버튼을 눌러 쿼리문을 제공받습니다. Application Insights에서 traces 항목에 데이터가 저장됩니다. 다음과 같이 query문을 작성할 수 있는 창으로 넘어옵니다. 다음은 제가 test한 실험값을 얻기 위해 작성한 query문 입니다. azure query # traces탭 안에 있는 값만 가져옵니다. traces # 24시간 안에 ..
 [AWS Lambda] AWS Lambda로 MapReduce 작업을 돌려보기 - 2
[AWS Lambda] AWS Lambda로 MapReduce 작업을 돌려보기 - 2
이번 포스트에서는 AWS Lambda로 MapReduce실험을 실제로 돌려보고 어떻게 동작 하는지에 대해 정리했습니다. 원문 내용의 주소와 깃헙 주소는 다음과 같습니다. https://aws.amazon.com/blogs/compute/ad-hoc-big-data-processing-made-simple-with-serverless-mapreduce/ https://github.com/awslabs/lambda-refarch-mapreduce 다음의 블로그를 참조하여 이해해 큰 도움을 얻었습니다. 코드에 대한 자세한 설명을 포함하므로 본 포스트를 읽기 전에 참고해 보시면 좋을 것 같습니다. https://jeongchul.tistory.com/622?category=495790 python3.6으로 구동..
AWS Lambda로 MapReduce 작업을 구현되어있는 코드를 수정하여 구성해볼 것 입니다. 이번 포스트에서는 원문에서 코드가 python2.6의 버전만을 지원하므로 python3.6으로 돌릴 수 있도록 변경해 볼 것 입니다. 원문 내용의 주소와 깃헙 주소는 다음과 같습니다. https://aws.amazon.com/blogs/compute/ad-hoc-big-data-processing-made-simple-with-serverless-mapreduce/ https://github.com/awslabs/lambda-refarch-mapreduce 다음의 블로그를 참조하여 이해해 큰 도움을 얻었습니다. https://jeongchul.tistory.com/622?category=495790 pytho..